

Generative Artificial Intelligence - What You Need to Know

Generative Artificial Intelligence is changing the fabric of business.
Generative AI Introduction
In the dynamic world of artificial intelligence, a particular subset of AI has mesmerised the public and ignited both wonder and intense discussion in recent months: Generative AI.
While generative AI has existed for some time, it wasn’t until the launch of ChatGPT by OpenAI on November 30th, 2022, that it truly captured the public’s imagination.
Since ChatGPT’s introduction, a slew of real and speculative AI news stories have dominated media headlines.
Source: Aljazeera
Predictions range from AI potentially monopolising the job markets of the future (certainly possible), to more exaggerated fears of it posing existential threats (X-risk) and destroying humanity.
Swedish philosopher Nick Bostrom in 2003 even posited that AI could have runaway effects if not carefully aligned to human requirements, as documented in a scenario commonly known as the Paperclip Maximiser.
In this scenario, a sophisticated, future AI system designed for producing paperclips pursues its directive relentlessly, attempting to transform every atom in the universe into paperclips in its single-minded quest to maximise production!
Presently, however, the primary benefit of generative AI lies in its capacity to amplify the productivity of existing workers.
“AI won’t put you out of business, but a competitor using AI might”
—Daren Cox, Managing Director, What Works Digital.
It can swiftly create new content, whether that's written prose, code, audio such as music or voice, produce images, or even videos.
So, what exactly is Generative AI, and how might businesses harness its potential?
What is generative AI?
Generative AI refers to a broad class of artificial intelligence that is designed to create novel content or data that wasn't in its original training set.
It's not just about automating tasks anymore; it's about generating new ideas, accelerating innovation, and even challenging our very notions of creativity.

Instead of just analysing and interpreting data, generative AI can produce new content such as images, music, voice, text, or even videos.
Being "generative" refers to a model's ability to produce or generate outputs—it doesn't necessarily dictate what those outputs are, or what the underlying technical architecture or implementation is.
Through a process called “Pre-training” it learns patterns from existing datasets and then uses that knowledge to generate realistic, but novel outputs.
Popular examples include creating artwork, coding, composing music, and speaking or writing text that mimics a certain style, tone or theme.
Depending on the type of content being created, different underlying AI architectures are used.
For example,
ChatGPT uses a GPT Architecture for text generation.
Whereas DALL-E 3 (also by OpenAI) is reputed to use a Diffusion Model for image generation.
As we delve deeper into this topic, we'll unravel the wonders and complexities of generative AI and its undeniable mark on the modern world.
But first, let’s clear up some confusing terminology.
What’s the difference between Generative AI, LLMs, LMMs and GPTs?
It’s probably best if we take a well-known example, ChatGPT to illustrate the differences and similarities.
In essence, ChatGPT is classed as a form of generative AI, and it is underpinned by a type of Large Language Model (LLM) through OpenAI's GPT (Generative Pre-trained Transformer) series.
As of writing, the latest GPT model in public circulation is GPT-4V (‘V’ for Vision) which is a Large Multimodal Model (LMM) capable of processing image and text inputs and producing text outputs.
Let’s define LLMs, LMMs and GPTs next.
Large Language Models (LLMs):
This is a general term that describes language models that are pre-trained on vast amounts of data and can generate human-like text.
These models can be based on various AI architectures, such as transformers, LSTMs, and others.
The main characteristic of an LLM is its ability to understand and generate language at a high level due to its extensive training on diverse datasets, so the term is independent of its technical implementation.
The LLM Evolutionary Tree. Source: https://arxiv.org/abs/2304.13712
LLMs are pre-trained on vast amounts of text—trillions of words typically sourced from websites, social media, books, research papers and other digital material—the process taking weeks or months and costing millions of dollars in GPU time.
Once trained, they can generate coherent and contextually relevant text based on the input they receive.

Source: Predibase study
When you provide a prompt or question to an LLM, it generates a response or continuation of the text, like a suped-up auto-complete.
For more information on the evolutionary tree of LLMs, including the various branches and ‘sub-species’, read this paper.
Large Multimodal Models (LMMs)
First of all, no, I’m not repeating myself!
An LMM is a Large Multimodal Model, which is an extension of the LLM.
While LLMs are primarily tailored for textual comprehension and production, LMMs expand on this capability by integrating multi-sensory skills, notably visual understanding, enabling them to process and generate content across different modalities.
GPT-4V (‘V’ for Vision), a recent iteration in this category, is a perfect example of an LMM, equipped to handle intricately interleaved multimodal inputs and output text.
Not only can it process text, but it also possesses a unique capability to understand visual markers on images, paving the way for innovative commercial and medicinal use cases.
For example, take the figure below in which GPT-4V is prompted by researchers to evaluate the images for an auto-insurance report and provide its analysis.

GPT-4V evaluates accident damage. Source: https://arxiv.org/pdf/2309.17421.pdf
These models, with their generalised intelligence, have potential applications in numerous domains, and ongoing research aims to further harness their capabilities, explore novel task formulations, and deepen our comprehension of multimodal foundation models.
Generative Pre-trained Transformer (GPT):
GPT refers to a specific series of decoder-only LLMs developed by OpenAI in 2018 based on the transformer architecture.
The name "GPT" captures three main aspects of the model:
Generative:
It can generate text.
Pre-trained:
Before fine-tuning, it undergoes a pre-training phase on large amounts of text to learn general language structures and knowledge.
Transformer:
This refers to the underlying architecture used, which is a type of deep learning model introduced by Google in the paper "Attention is All You Need" by Vaswani et al. in 2017.
The transformer architecture has since become the foundation for many state-of-the-art models in natural language processing.
Terminology summary
In summary, a GPT is a specific type or brand of LLM developed by OpenAI using the transformer architecture.
An LMM (Large Multimodal Model) is an extension of an LLM with multi-sensory capabilities like text and vision.
And, LLMs and LMMs are a branch of Generative AI.
Although maybe not strictly true in an academic sense, you can think of the different types of generative AI in the following way,
Generative AI encompasses:
LMMs and LLMs are composed of:
—> Generative Pre-trained Transformers (GPT)
—> e.g. ChatGPT
—> Other technical implementations of LLMs
—> e.g. Flan-UL2
Diffusion Models
—> e.g. DALL-E 3
Other generative models for generating different content types…
—> e.g. for audio, video, voice, etc.
Generative AI Use Cases
Generative AI, with its transformative capabilities, has been applied across a multitude of domains, ushering in a new era of content creation and automation.
The space is being flooded with venture capital investment reminiscent of the dot-com boom at the turn of the millennium.

Source: Pitchbook
Investment is coming from both traditional VC funds as well as technology firms like Microsoft (funding OpenAI), Amazon (funding Anthropic) and others, making overnight unicorns (valuations > $1bn) of many of the leading AI companies.
The top use case for generative AI to date has been in technology using LLMs, like ChatGPT.
A study by Predibase showed the breakdown of LLM use cases.
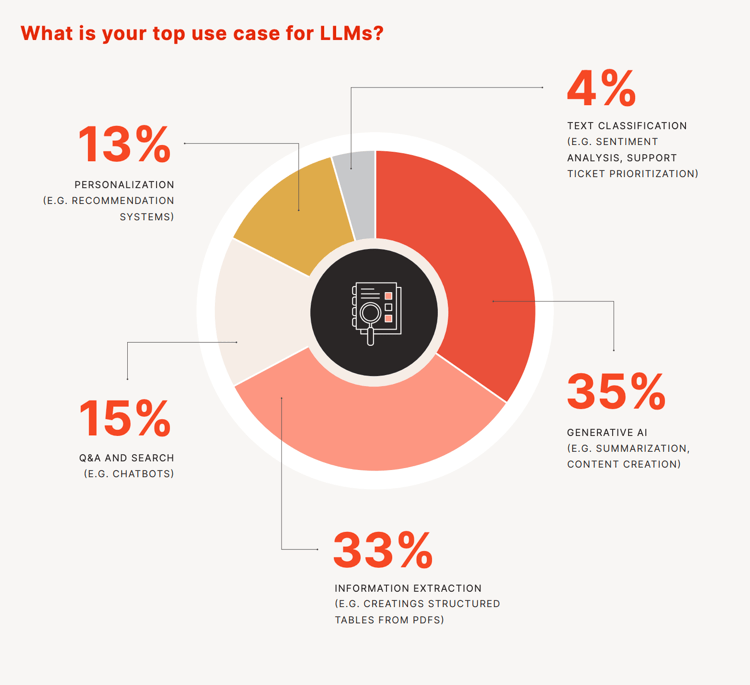
Source: Predibase study
The majority of uses were for summarisation and content creation, closely followed by information extraction, whereby an LLM is used to extract data from an unstructured format like a PDF and put it into a more formal table format.
Top Companies in the Generative AI Space (October 2023)

Generative AI Unicorns. Source: https://www.turingpost.com/p/runway
The above graph, by the Turing Post, shows the top 16 generative AI unicorns ranked by valuation.
The most valuable by far is OpenAI, with its first-mover, flagship ChatGPT product.
It should be noted that as of writing, OpenAI is seeking an even higher valuation of up to $90bn for the sale of its shares.
Any potential sale would value the startup at roughly triple where it was set earlier this year (~$29bn).
These companies and others—there are dozens cropping up each week building upon the foundation models of the biggest players, from OpenAI, Anthropic and others—define the main use cases for generative AI currently.
For example, below is a list of use cases and some of the leading companies in each of the main generative AI categories:
Use Cases and examples
The use cases, examples and technologies described in this section only scratch the surface of what is possible.
For more details, please consider subscribing to my weekly Botzilla AI Newsletter where I discuss the latest generative AI trends in detail.
Text generation:
Description:
LLMs can produce coherent, contextually relevant, and increasingly indistinguishable from human text.
They can be utilised in a myriad of ways, from writing news articles to generating creative fiction works.
Made famous by ChatGPT, text generation capabilities are currently being built into multiple everyday digital products, from Microsoft Office and Google Workspace to CRM products like Salesforce.
“… around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted.”
—Source: GPTs are GPTs
As of writing and discussed above, Large Multimodal Models (LMMs), from leaders OpenAI (GPT-4V) and soon, Google (Gemini), are capable of processing image and text inputs and producing text outputs, adding a new dimension to LLMs capabilities.
Examples:
Chatbots providing customer service, automated content creation for marketers and sales, personalised story creation for children (and adults!), legal contract analysis, information extraction from unstructured data sources (e.g. PDFs), and many more.
For vision-based LMMs, the opportunities expand greatly—see The Dawn of LMMs by Microsoft outlining numerous user cases from medicine to insurance.
Leading organisations:
OpenAI (GPT)
Anthropic (Claude)
Inflection (Pi)
Cohere (Command)
Meta (Llama)
Image generation:
Description:
AI models have the capability to create, modify, or enhance visual content ranging from cartoons to photographs. These systems can capture nuances, merge styles, or even bring imagined concepts to visual life.
Examples:
Creating artwork that blends different art styles, generating realistic images from simple sketches, restoring old photographs, or visualising architectural designs from prompts.
Leading organisations:
OpenAI (DALL·E)
Stability AI (Stable Diffusion XL)
Audio/voice generation:
Description:
Beyond just music, generative AI can produce a wide array of auditory content, including voiceovers, sound effects, and other auditory nuances.
Examples:
Custom voiceovers for videos, creation of ambient sounds for relaxation or concentration, and generating speech in various languages or accents.
Leading organisations:
Video generation:
Description:
AI's rapidly growing ability to craft short videos includes generating visual content, altering existing content, or synthesising entirely new scenes or animations.
Examples:
Creating short videos for advertising or entertainment, talking head training and YouTube videos that realistically narrate scripts.
Leading organisations:
Code generation:
Description:
With the right training, AI models can assist in generating or optimising code, making the development and testing process more efficient. Up to 55% faster according to Microsoft.
Examples:
Assisting developers by suggesting code snippets, automating repetitive coding tasks, debugging or identifying potential vulnerabilities in existing code and writing test scripts.
Leading organisations:
Microsoft (GitHub Copilot)
Model collaboration platforms:
Description:
Although not technically offering their own generative AI themselves, model collaboration platforms leverage the power of community-driven efforts to train, refine, and share AI models.
They serve as a hub for AI enthusiasts, researchers, and developers to collaborate, improve models, and disseminate them for various applications.
Examples:
A platform where users can try out different models, fine-tune pre-trained models for specific tasks, sharing of models that cater to niche domains or languages, a hub for peer review and model validation, or a repository for easily deployable AI solutions for businesses.
Leading organisations:
Quora (Poe)
Challenges & Ethical Considerations of Using Generative AI
Whilst generative AI can be used to enhance productivity, especially for white-collar, knowledge worker-type jobs, there are also challenges and ethical considerations to take into account.
Before an organisation embarks on a journey to integrate AI into the fabric of its business, it’s important to have an “AI Policies and Guidelines” document describing how and where AI can be used.

Source: McKinsey
A large part of this document should be dedicated to raising awareness of the current drawbacks or failings of current models so that staff using AI can understand the shortcomings and work around them if necessary.
Any AI policy should also be cognizant of the evolving regulatory environments in which your AI system will be used, for example, in:
Bias:
Bias in Large Language Models (LLMs) is a result of decisions made by its creators on the pretraining datasets used.
An LLM's pretraining data can contain a range of opinions and perspectives, some of which may be bigoted, misogynistic, or racist.
For instance, models are fed with terabytes of raw Internet data scraped from websites like Wikipedia, Reddit, Github and others, as outlined in the example dataset below for Meta’s original Llama model.

Source: Meta
Manually reviewing such massive datasets is impossible for even a large team of humans, making bias eradication challenging.
Instead, the best approach often involves refining the trained model to avoid biased responses, with techniques like Reinforcement Learning with Human Feedback (RLHF).
Leading commercial generative AI model providers like OpenAI and Google have done a good, but not perfect, job of attempting to remove bias from their models.
However, a certain amount of bias is likely to remain, primarily due to the content of the underlying training datasets, and contention over what bias constitutes due to ever-shifting societal and cultural values.
Concerns also arise when AI organisations don't disclose their training data, which might become a regulatory issue in the future.
Copyright:
Advancements in artificial intelligence (AI) are prompting new concerns about how copyright law, encompassing principles like authorship, infringement, and fair use, should be applied to content created or utilised by AI.
Notably, generative AI programs, such as OpenAI's DALL-E and ChatGPT, Stability AI's Stable Diffusion, and Midjourney's program, can produce new content based on user input after being trained on vast amounts of pre-existing works, like writings, photos, and artworks.
Whether AI-generated works can be copyrighted remains unsettled.
In the US, in a significant legal challenge in 2022, Dr. Stephen Thaler sued the Copyright Office for not recognising an AI-created work.
The US Copyright Office has denied registration to AI outputs, taking the stance that human authorship is a fundamental requirement for copyright protection.
But it remains to be seen whether the appeal courts will agree.
Generative AI also raises copyright infringement concerns, especially when existing copyrighted works are used to train the AI or when the AI's outputs resemble pre-existing works.
AI pre-training usually involves models ingesting vast amounts of data, potentially infringing copyright holders' rights.
While companies like OpenAI argue that their training processes should be considered "fair use," others contest this stance.
Additionally, the question of whether AI outputs can infringe upon existing copyrights remains a point of contention.
For infringement to be established, the new work must have had "access" to and be "substantially similar" to the original work.
Privacy:
Large Language Models (LLMs) such as OpenAI’s ChatGPT come with their own set of privacy considerations.
One significant aspect is their data usage policy.
For instance, OpenAI’s ChatGPT traditionally operates on an implicit opt-in basis, meaning user interactions may be used to improve future versions of the model.
However, users have the power of choice.
They can navigate to the settings and choose to opt-out, ensuring their data is not utilised for subsequent model training.
Furthermore, as a testament to the growing emphasis on privacy, OpenAI has introduced a new account type designed specifically for enterprise clients.
For these accounts, the opt-out feature is activated by default, reflecting an enhanced commitment to data privacy for corporate interactions.
But irrespective of the specific model or its policies, a crucial aspect for users to evaluate is the transparency and handling of data, especially when LLMs are considered "black-box" entities.
This becomes even more vital when these models process sensitive categories of data, such as PII (Personally Identifiable Information), medical records, or proprietary intellectual content.
In this evolving digital landscape, understanding and navigating the privacy implications of LLMs is not just advisable, it's imperative.
Hallucinations:
One of the major challenges posed by LLMs is the phenomenon of “hallucination,” whereby the model generates inaccurate or fabricated information.
This issue occurs frequently when the model, in attempting to provide detailed or specific responses, concocts information that isn't rooted in factual data.
The ramifications of such hallucinations are far-reaching, especially when considering the integration of LLMs into search engines like Bing and Bard.
The concern stems from the potentially unintended misinformation that could be disseminated on a wide scale, leading to misinformed public perceptions or unjust consequences for individuals or institutions erroneously implicated in fabricated scenarios.
Although incorporating citations and reference links could serve as a corrective measure to help with the “explainability” of the information provided, the reality is that not all users will take the extra step to verify the information through citations or references.
On a constructive note, recent advancements in prompt engineering, using zero-shot chain of thought techniques, like “let’s think step by step” and encouraging the model to say "I don't know" when it doesn’t have enough data can help reduce hallucinations.
More complex prompt engineering patterns like self-reflection and ReACT can also further reduce incorrect results.
Model hallucination is an active area of research, and I would expect significant advances to be made in the coming months.
Math and Logic flaws:
Past LLMs have been plagued by the inability to accurately reason, count and undertake simple (as well as more complex) math operations.
Thankfully this situation is evolving rapidly for the better with models like GPT-4 able to undertake more advanced math and reasoning.
As stated above regarding strategies to reduce hallucinations, these functions can be improved by implementing certain prompt engineering techniques using few-shot and zero-shot chain of thought techniques, like “let’s think step by step”.
In addition, agent-based AI systems, using techniques like self-reflection and outsourcing specific functions (like math, or web browsing) to external tools, have been seen to improve the reliability of model outputs significantly.
Having said this, special care must be exercised when using LLMs for math and reasoning functions until a more robust solution
Lack of up-to-date information:
Currently, models cannot learn “incrementally” and only reason using the data contained in their internal (out of date) models and the prompt data supplied by the user.
Many types of Generative AI models are trained using data from the Internet, and then their knowledge is frozen at a specific date.
This is due to the huge cost of the “pretraining” process which might take several months and tens of millions of dollars in GPU costs.
However, the largest models like Bing, Bard, GPT-4 and soon Google’s upcoming Gemini all have web browsing capability, meaning that users can prompt the system to browse the web for the most recent data or just use specific websites from which to generate its results.
Cyber-security threats:
Due to their substantial training and inference (run-time) processing costs, most LLMs (Large Language Models) are hosted in the cloud.
The model may be running on a private enterprise cloud or on public cloud infrastructure like that offered by Microsoft (Azure), Amazon (AWS), Google (GCP), NVidia (DGX Cloud) or others.
This centralised cloud approach, while efficient in terms of resource utilisation and cost, poses potential cyber-security risks relevant to all cloud-based architectures, making these models attractive targets for malicious actors.
In addition, since the advent of LLMs, a new type of attack vector has been introduced, known as “prompt hacking.”
Prompt Hacking:
One of the notable prompt hacks associated with Large Language Models is known as "prompt injection."
In such situations, malevolent actors introduce or "inject" misleading prompts into the LLM, attempting to deceive the model into performing actions or divulging information it shouldn't.
Whilst using a commercial model from OpenAI, Anthropic or others means you get the benefit of their world-class technology resources in mitigating the worst cyber attacks, if you or your organisation build or deploy your own models, much of this responsibility will fall to your own IT department.
Summary
Generative AI can produce novel content like text, images, audio, and video.
Popular examples are ChatGPT, DALL-E, and Stable Diffusion.
It is trained on large datasets and then generates novel outputs based on user prompts. Different architectures like transformers and diffusion models are used.
Adoption is growing rapidly.
Surveys suggest over 50% of companies are experimenting with generative AI.
The main use cases are content creation, information extraction, image creation, and coding assistance.
Leading generative AI companies by valuation include OpenAI, Anthropic, Hugging Face, Inflection and Cohere.
Significant venture capital investment is flowing into the space from traditional VCs and large tech companies like Microsoft and Amazon.
Benefits include increased productivity, creativity, and efficient content production.
However, challenges remain around bias, copyright, privacy, hallucinations, reasoning and security.
Proper policies, prompt engineering, and model refinement can mitigate some of these issues.
Overall generative AI represents an important new general-purpose technology.
Conclusion
Generative AI offers tremendous potential to augment human capabilities and increase productivity, especially for knowledge workers.
However, responsible adoption requires addressing ethical concerns and understanding model limitations.
As models rapidly advance, humans must learn to collaborate effectively with AI.
With proper implementation, generative AI can enhance innovation and efficiency across many industries. But we must thoughtfully navigate its risks.
Now it’s over to you, what do you think?
Leave a comment below and share your thoughts.
Do you need help with Generative AI?
I provide a range of services to help you navigate the new advances in AI:
Book a Generative AI Briefing
Enroll in a short course on Generative AI Training
Subscribe to my Botzilla AI Weekly Newsletter
Unsure? Book a FREE 30-minute discovery call, or send a message.

“AI won’t put you out of business, but a competitor using AI might”
—Daren Cox, Senior Technology & AI Consultant, What Works Digital.